추천시스템
개요
AI를 활용하는 분야가 대표적으로 이미지, 자연어, 추천 으로 분리되있다고 생각했다. 왜냐하면 취업 시장에서 위 세 가지를 개별적이나 조합해서 많이 구직하고 있기 때문이다. 이미지로 AI를 시작했지만 사람들이 좋아하는, 그리고 필요할 때 나타내주는 추천시스템 또한 꼭 배우고 싶은 기술이였다. 또 수학과 연관이 깊기 때문에 전공을 살려 공부를 할 겸 익혀야 필요성을 항상 염두에 두고 있었다. 그래서 그 개념부터 정리해보려한다.
추천시스템이란?
추천 시스템은 사용자의 스타일을 파악하고 그것에 따라 상품을 추천해 주는 것이다.
예로 유튜브, 넷플릭스, 홈쇼핑 등에서 사람들이 남긴 흔적들을 이용해 나도 모르는 사이 나에게 딱 맞는 서비스들을 제공해준다. 특히 넷플릭스는 추천시스템을 강조하면서 추천대회 같은 것들을 지속적으로 열어 회사의 성장을 견인했다. 이런점에서 많은 기업이 추천 시스템에 큰 관심을 갖게 되었다.
추천시스템 Type
- content based filtering
- collaborative filtering
- hybrid filtering
1. Content based filtering
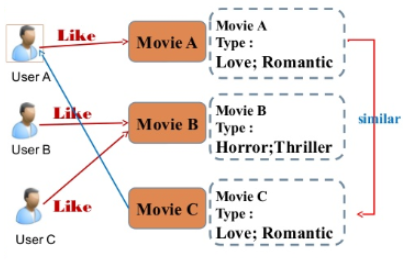
- 아이템에 대한 데이터를 이용하여 어떤 사람이 특정 아이템을 선호한다면, 그것과 비슷한 아이템을 추천하는 방식
- ex) 내가 닥터스트레인지 대혼돈의 멀티버스를 보고 그 영화에 높은 평점을 줬다고 하자. 그럼 그 영화의 감독인 샘레이미 감독이고 마블장르인 스파이더맨이 추천해주는 것이다.
- 장점
- 다른 사용자의 데이터와는 별개다.
- 새로 추가된 신작이나 유명하지 않은 아이템도 추천 가능
- 아이템의 feature를 이용해 아이템간의 유사성을 계산하기 때문에 feature의 특징을 근거로 잘 삼을 수 있다.
- 단점
- 아이템의 feature를 구성하는 과정에서 주관성이 강해진다.
- 나는 닥터스트레인지가 마블이라고 생각해서 봤지만 다른 사람은 호러 공포영화라고 생각하고 호러를 기대할 수 있다.
- 과거의 데이터가 없다면 추천이 어렵다. (신규 가입에 경우 추천할 것이 없다)
- 추천 과정에서 아이템의 feature 정보 간 연관성을 바탕으로 해서 사용자가 이미 알고 있거나, 친숙한것만 추천하는 문제
- 필터 버블(Filter Bubble) : 사용자에게 제한된 주제로만 정보를 제공하는 현상, 이렇게 되면 다양한 생각들을 할 수 없고 스스로 가치판단이 힘들다.
- ps. 개인적으로 이게 정말 심각한 문제라고 생각한다. 유튜브 같은 경우 특정 정치 성향을 갖게 되면 계속 한 곳으로만 편향된 정보를 제공하는 유튜브들만 뜨고 자신과 다른 정치성향의 유튜브가 나타날시 바로 넘겨서 다양한 생각들을 못하게 되는 것 같다. 대한민국의 양극화가 생긴 원인 중 하나가 아닐까 생각한다..
- 필터 버블(Filter Bubble) : 사용자에게 제한된 주제로만 정보를 제공하는 현상, 이렇게 되면 다양한 생각들을 할 수 없고 스스로 가치판단이 힘들다.
- 아이템의 feature를 구성하는 과정에서 주관성이 강해진다.
- 유사 컨텐츠를 찾는 방법

- 코사인 유사도 : 두 점 사이의 각도를 측정한 지표로, 값이 작으면 두 데이터가 가까이 있다.
- 유클리드거리 : 두 점 사이의 거리를 측정한 지표로, 값이 작으면 두 데이터가 가까이 있다.
- 맨하탄거리 : 두 점 사이의 거리를 측정하지만, 수평 수직으로만 이동하는 거리를 구한다.
- 그럼 어떻게 유사한 아이템을 찾는지 알아보자. 여기선 간단한 수학적 이론이 들어간다.
(내일 쯤 한 번 이걸 이용한 코드들을 구사해봐야겠다. 그 후 하이퍼링크를 첨부하겠다.)
2. Collaborative filtering
- Content based filtering이 내가 좋아하는 개인적 성향에 중심이라면
- Collaborative filtering은 나랑 성향이 비슷한 친구들이 본 영화를 찾아본다.
- ex) 내가 닥터스트레인지를 봤다고 하자. 그럼 같이 닥터스트레인지를 본 다른 시청자들이 본 영화를 나에게 추천
- 협업 필터링의 종류
- Memory-Based Approach
- 유사한 사용자나 아이템을 사용
- 최적화 방법이나 매개변수를 학습하지 않고 단순히 산술 연산만 사용
- 코사인 유사도 or 피어슨 상관계수를 사용
- 장점
- 쉽다.
- feature의 근거를 설명하기 쉽다.
- 도메인에 의존적이지 않다고 한다;
- 단점
- 데이터가 부족할 경우 성능이 무척 낮다
- 데이터가 너무 많으면 속도가 무척 저하된다.
- Model-Based Approach
- 기계학습을 통해 추천
- 최적화방법, 매개변수를 학습
- 행렬분해, SVD, NN 를 사용
- 장점
- 데이터가 부족해도 성능을 높힐 수 있다.
- 단점
- feature의 근거를 설명하기 힘들어진다.
-

- Memory-Based Approach
-

- User-based //// Item-based
- User-based
- 특정 사용자 선택
- 평점 유사도를 기반으로 나와 유사한 사용자를 찾음
- 유사한 사용자가 좋아한 Item을 추천
- ex) 윗 그림에서 34를 시청한 U1,U3 중 U1의 1번을 U3에게 추천
- Item-based
- 특정 아이템을 선택
- 특정 아이템을 좋아한 사용자를 찾음
- ex) 3번 영화를 좋아한 사용자는 1번 영화도 좋아하더라
User-based 계산
참고 : (https://abluesnake.tistory.com/117?category=1204978)
| Item 1 | Item 2 | Item 3 | Item 4 | Item 5 | |
|---|---|---|---|---|---|
| A | 5 | 4 | 4 | 3 | |
| B | 1 | 0 | 1 | 4 | |
| C | 4 | 4 | 5 | 3 | |
| D | 2 | 1 | 4 | 3 | |
| E | 4 | 4 | 4 | 2 | |
| F | 4 | 2 | 3 | 1 |
사용자 B와 D가 얼마나 유사한지를 코사인 유사도를 사용하여 계산

| A | B | C | D | E | F | |
|---|---|---|---|---|---|---|
| A | 0.84 | 0.96 | 0.82 | 0.98 | 0.98 | |
| B | 0.84 | 0.61 | 0.84 | 0.63 | 0.47 | |
| C | 0.96 | 0.61 | 0.97 | 0.99 | 0.92 | |
| D | 0.82 | 0.84 | 0.97 | 0.85 | 0.71 | |
| E | 0.98 | 0.63 | 0.99 | 0.85 | 0.98 | |
| F | 0.98 | 0.47 | 0.92 | 0.71 | 0.98 |
다음처럼 전체 사용자간 유사도 행렬을 구할 수 있다.
마지막으로 B가 Item4에 대한 평점을 예측 해보자

B는 Item4에 대해 3.92라는 높은 평점을 부여할 것으로 예상할 수 있다.
Item based의 계산 Item을 기준으로 유사도를 계산하면 구할 수 있다.
이렇게 계산만을 위한 memory based까지 살펴봤다.
다음에는 코드로 직접 구현하거나 NN을 사용한 model-based를 살피겠습니다…..
알고리즘 공부하러갑니다…