드디어 깃허브 스타일 적용에 성했다. 앞으로는 보기 편하게 이렇게 올릴수 있을것 같다.
0
- 지금까지는 최소 제곱법을 이용해 다항식 곡선 피팅을 했다.
- 최대 가능도 접근법에서 확인 한 것처럼 훈련 집합에서의 좋은 성능이 반드시 좋은 성능을 보장해주진 않는다.
- 과적합 때문이다.
- 이를 해결하기 위해 데이터가 충분할 경우 일부의 데이터만 사용해서 다양한 모델과 모델의 매개변수들을 훈련시키고 독립적인 데이터 집합인 검증집합에서
- 이 모델과 매개변수를 비교/선택하는 것이다.
- 그 후 test set으로 모델의 최종 성능을 확인한다.
- 하지만 대부분의 실제 경우에는 데이터의 공급이 제한적이고 데이터가 크지 않은 경우가 많다.
- 그 때 사용하는 방법이 교차 검증법(cross validation) 이다.
1. 교차 검증법(cross validation)
- 랜덤으로 (S-1)/S 비율 만큼 훈련에 사용하고, 1/S를 테스트 셋으로 사용
- 그림으로 보는게 이해가 더 빠를듯 싶다.
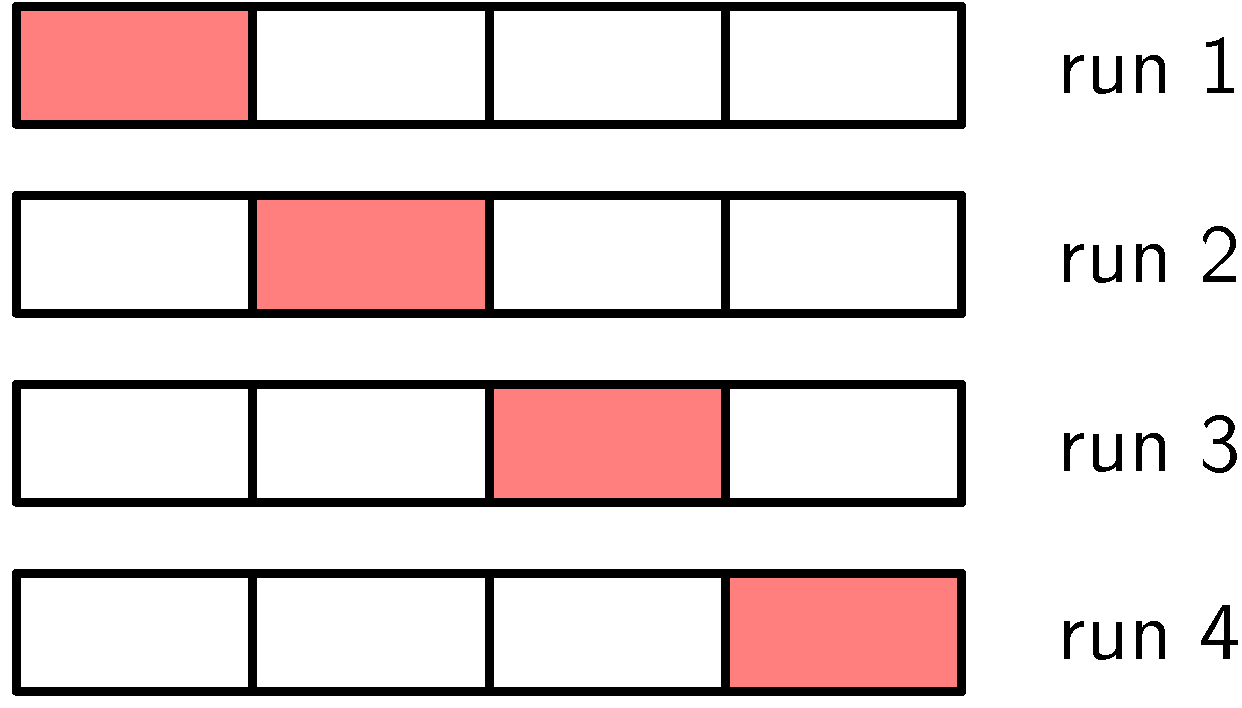
- S=4
- 빨간 부분은 훈련을 안시키는 남겨두는 부분이다.
- 따라서 (S-1)개의 집합을 이용해 훈련하고 마지막 한 개로 평가하는 방식이다. - 이렇게 S번 실행해서 성능 점수들을 평균내어서 최종 성능 점수를 도출한다.
- 단점
- S의 수가 늘어남에 따라서 모델 훈련의 시행 횟수가 늘어난다.(즉 계산이 복잡해진다)
- 한 가지 모델에 여러 가지의 복잡도 매개변수가 있을 경우, 각각의 맞는 복잡도 매개변수(하이퍼 파라미터)를 조합하는 훈련 실행수를 계산해야한다.
- 이상적인 상황은 학습데이터 집합만 사용하고 반복되는 작업 없이 한번에 여러 모델을 비교할 수 있어야한다.
- 그리고 과적합으로 인한 편향ㅇ로 부터 자유로워야 한다.
2. 정보 기준
- 이는 최대 가능도 방법의 편향 문제에 대한 대안으로 제시
- 과적합이 일어나지 않도록 페널티항을 추가하는 방식
- ex) 아카이케의 정보량 기준(AIC, 영어로 하니까 더 쉽다 ㅋㅋ)
- $lnp(D|w_{ML}) - M$ (1.73)
- 여기서 M은 모델의 수정 가능한 파라미터수(페널티)
- $p(D|w_{ML})$은 가장 잘 피팅된 로그 가능도
- 베이지안 정보 기준(BIC)가 또 있는데 이건 나중에 논의한다고 한다.
- 중요한 것은 모델 매개변수들의 불확실성을 고려하지않고 실제에서 과하게 간단한 모델을 선택하긴 하지만 과적합을 방지해준다는점을 알아두자.
3. AIC, BIC BASIC
- 옛날 adsp 준비하면서 봤던 공부했던 개념이라 그냥 한번 더 공부하고 넘어가려 한다.
- AIC
- AIC는 주어진 데이터 셋에 대한 통계 모델의 상대적인 품질을 평가
- 보통 낮을수록 좋다.
- 위 식과는 다르게 부호가 반대로 되있다.
- AIC = -2log(likelihood) + 2k(페널티)
- 변경가능한 파라미터수가 많을수록 AIC는 좋지 않은 성능을 가진다.
- BIC
- AIC와 비슷하지만 마지막 패널티를 수정하면서 조금 달라졌다
- BIC = -2log(likelihood) + log(n)K
- n이 변수로서 변수가 많을수록 AIC보다 더 강하게 페널티를 가한다.
- 결론적으로 변수 개수가 작은 것이 우선이라면 AIC보다 BIC가 더 강한 힘을 갖는다.